Microservices is a trending topic among software engineers today. Let’s understand how we can build truly modular, business agile IT systems with Microservices architectural style.
Microservices Concept
Microservices architecture consists of collections of light-weight, loosely-coupled services. Each service implements a single business capability. Ideally, these services should be cohesive enough to develop, test, release, deploy, scale, integrate, and maintain independently.
Formal Definition “Microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.”- James Lewis and Martin Fowler
Defining Characteristics of Microservices
- Each service is a light-weight, independent, and loosely-coupled business unit.
- Each service has its own codebase, managed and developed by a small team (mostly in an agile environment).
- Each service is responsible for a single part of the functionality (business capability), and does it well.
- Each service can pick the best technology stack for its use cases (no need to stick into one framework throughout the entire application).
- Each service has its own DevOp plan (test, release, deploy, scale, integrate, and maintain independently).
- Each service is deployed in a self-contained environment.
- Services communicate with each other by using well-defined APIs (smart endpoints) and simple protocols like REST over HTTP (dumb pipes).
- Each service is responsible for persisting its own data and keeping external state (Only if multiple services consume the same data, such situations are handled in a common data layer).
Benefits of Microservices
Microservice are made to scale large systems. They are great enablers for continuous integration and delivery too.


- Independent scaling — Microservices architecture supports Scale Cube concept described in the excellent book The Art of Scalability. When developing microservices to achieve functional decomposition, the application automatically scales via Y axis. When the consumption is high, microservices can scale via X axis by cloning with more CPU and memory. For distributing data across multiple machines, large databases can be separated (sharding) into smaller, faster, more easily managed parts enabling Z axis scaling.
- Independent releases and deployments — Bug fixes and feature releases are more manageable and less risky, with microservices. You can update a service without redeploying the entire application, and roll back or roll forward an update if something goes wrong.
- Independent development — Each service has its own codebase, which is developed, tested, and deployed by a small focused team. Developers can focus on one service and relatively-small scope only. This results in enhanced productivity, project velocity, continuous innovation, and quality at source.
- Graceful degradation — If a service goes down, its impact won’t propagate to the rest of application and result in a catastrophic failure of the system, allowing a certain degree of anti-fragility to manifest.
- Decentralized governance — Developers are free to pick the technology stacks and make design standards and implementation decisions that are best suited for their service. Teams do not have to get penalized due to past technology decisions.
Operational Concerns
Independent services alone cannot form a system. For the true success of microservices architecture, significant investments are required to handle cross-system concerns like:
- Service replication — a mechanism by which services can easily scale based upon metadata
- Service registration and discovery — a mechanism to enables service lookup and finds the endpoint for each service
- Service monitoring and logging — a mechanism to aggregate logs from different microservices and provide a consistent reporting
- Resiliency — a mechanism for services to automatically take corrective actions during failures
- DevOps — a mechanism for handling continuous integration and deployment (CI and CD)
- API gateway — a mechanism for for providing an entry point for clients
Middleware & Design Patterns
API Gateway (Single entry point for all clients)

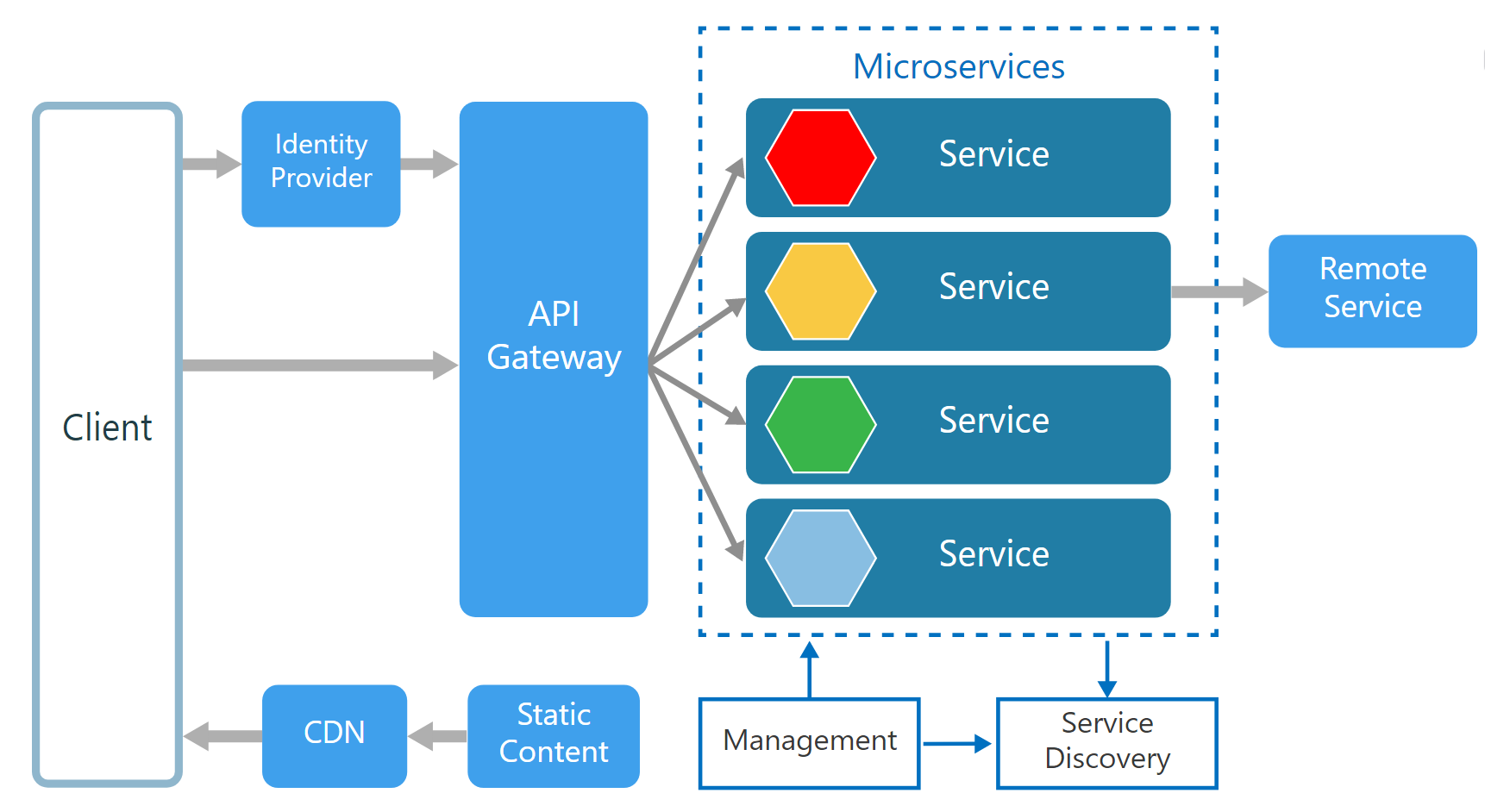
API Gateway acts as a single entry point for all clients as well as an edge service for exposing microservices to the outside world as managed APIs. It sounds like a reverse proxy, but also has additional responsibilities like simple load-balancing, authentication & authorization, failure handling, auditing, protocol translations, and routing. The development team can select one of the following approaches to implement an API Gateway.
- Build it programmatically — to have better customizations and control
- Deploy an existing API gateway product — to save initial development time and use advanced built-in features (Cons: Such products are vendor-dependent and not completely free. Configurations and maintenance often can be tedious and time-consuming)
Some design patterns that explain API Gateway behaviour are as follows (Read Design patterns for microservices).
- Gateway Aggregation — aggregate multiple client requests (usually HTTP requests) targeting multiple internal microservices into a single client request, reducing chattiness and latency between consumers and services.
- Gateway Offloading — enable individual microservices to offload their shared service functionality to the API gateway level. Such cross-cutting functionalities include authentication, authorization, service discovery, fault tolerance mechanisms, QoS, load balancing, logging, analytics etc.
- Gateway Routing (layer 7 routing, usually HTTP requests)— route requests to the endpoints of internal microservices using a single endpoint, so that consumers don’t need to manage many separate endpoints
Note that an API Gateway should always be a highly-available and performant component, since it is the entry point to the entire system.
Event Bus (Pub/sub Mediator channel for asynchronous event-driven communication)


For different parts of the application to communicate with each other irrespective of sequence of messages (asynchronous) or what language they use (language agnostic), event bus can be used. Most of event buses support publish/subscribe, distributed, point to point, and request-response messaging. Some event buses (like in Vert.x) allow client side to communicate with corresponding server nodes using the same event bus, which is a cool feature loved by full-stack teams.
Service Mesh (Sidecar for interservice communication)




Service Mesh implements Sidecar pattern by providing helper infrastructure for interservice communication. It includes features like resiliency (fault tolerance, load balancing), service discovery, routing, observability, security, access control, communication protocol support etc.


In practice, a Sidecar instance is deployed alongside each service (ideally in the same container). They can communicate through primitive network functions of the service. The Control Plane of Service Mesh is separately deployed to provide central capabilities like service discovery, access control, and observability (monitoring, distributed logging). Most importantly, Service Mesh style allows developers to decouple network communication functions from microservice code and keep services focused only on the business capabilities. (Read: Netflix Prana, Service Mesh for Microservices)
☝ Even though above images indicate direct connections between services, the nice way to handle the interservice communication would be using a simple Event Bus as a Mediator to keep coupling at a minimum level.
Backends for Frontends (BFF)

If the application needs to tailor each API to suit the client app type (web, mobile, different platforms), different rules (configs) can be enforced via a facade or can serve separate builds based on client capabilities. This can be implemented at the API Gateway level itself or in parallel to the services level. This pattern is useful for providing specific user experiences. However, the development team should be careful enough to keep BFFs upto a manageable limit.
Best Practices
✅ Domain Driven Design — Model services around the business domain.


✅ Decentralized Data Management (Avoid shared databases). When multiple services consume a shared data schema, it can create tight coupling at data layer. To avoid it, each service should have its own data access logic and separate data store. The development team is free to pick the data persistence method which best fit to each service and nature of data.


✅ Smart endpoints and dumb pipes — Each service owns a well-defined API for external communication. Avoid leaking implementation details. For communication, always use simple protocols such as REST over HTTP.
✅ Asynchronous communication — When asynchronous communication is used across services, the data flow does not get blocked for other services.


✅ Avoid coupling between services — Services should have loose coupling and high functional cohesion. The main causes of coupling include shared database schemas and rigid communication protocols.
✅ Decentralize development — Avoid sharing codebases, data schemas, or development team members among multiple services/projects. Let developers focus on innovation and quality at source.
✅ Keep domain knowledge out of the gateway. Let the gateway handle routing and cross-cutting concerns (authentication, SSL termination).
✅ Token-based Authentication — Instead of implementing security components at each microservices level which is talking to a centralized/shared user repository and retrieve the authentication information, consider implementing authentication at API Gateway level with widely-used API security standards such as OAuth2 and OpenID Connect. After obtaining an auth token from the auth provider, it can be used to communicate with other microservices.


✅ Event-driven nature — Human beings are autonomous agents that can react to events. Can’t our systems be like that? (Read: Why Microservices Should Be Event Driven: Autonomy vs Authority)
✅ Eventual consistency — Due to the high cohesiveness in microservices, it is hard to achieve strong consistency throughout the system. Development team will have to handle eventual consistency as it comes.
✅ Fault tolerance — Since the system comprises of multiple services and middleware components, failures can take place somewhere very easily. Implementing patterns like circuit-breaking, bulkhead, retries, timeouts, fail fast, failover caching, rate limiters, load shedders in such vulnerable components can minimize the risks of major failures. (Read: Designing a Microservices Architecture for Failure)
✅ Product engineering — Microservices will work well as long as it is engineered as a product, not as a project. It’s not about making it work somehow and delivering before the deadlines, but about a long term commitment of engineering excellence.
Microservices in Practice
When to use Microservices
Microservices architecture best fits for:
- Applications with high scalability needs
- Projects with high release velocity
- Business cases with rich domains or many subdomains
- Agile environments with small, cross-functional development teams developing large products collaboratively (Read: The Real Success Story of Microservices Architectures)
Some go-to frameworks for implementing microservices
- 🥇Vert.x — light-weight, simple to understand/implement/maintain, polyglot (support many languages), event-driven, non-blocking, so far the best performance and scalability when handling high concurrency needs with minimal hardware, unopinionated (only provides useful bricks, developers have freedom to be innovative and carefully build their applications, not like traditional restrictive frameworks)
- 🥈Akka — satisfactory performance, implements actor model, good for reactive & event-driven microservices
- 🥉SpringBoot/Cloud — easy to start (familiar paradigms), based on the good old Spring framework, a little bit heavy framework, many integrations available, large community support
- Dropwizard — good for rapid development of RESTful web services, comes fully-loaded with some of nice Java tools & libraries like Google Guava, Jetty server, Logback, Hibernate Validator, Joda Time, Jersey, and Jackson.
Deployment Options
- Containers — good for enforcing DevOp objectives (rapid development, reduced time to market, seamless scaling)
- Cloud — good for building reliable and scalable infrastructure to serve geographically-dispersed users
- Serverless — good for handling highly volatile traffics
- Maintain own IT infrastructure — good for those who have high capacities and resources to build entire infrastructure
Developing concepts around microservices
- Self-Contained Systems — assemble software from independent systems (like verticals in microservices)
- Micro Frontends — divide monolith web UIs into independent features that can be developed as self-contained UI components and communicate with directly with microservices
Keywords to google (and study!)
Domain Driven Design (DDD) | Bounded Context (BC) | Polyglot Persistence (PP)| Command and Query Responsibility Segregation (CQRS) | Command Query Separation (CQS) | Event-Sourcing (ES) | CAP Theorem | Eventual Consistency | Twelve-Factor App | SOLID Principles |
Architecture Suggestions







No comments:
Post a Comment