This topic will cover using design patterns to mitigate challenges with microservices, as described in the preceding section. Later in this book, we will see how we can implement these design patterns using Spring Boot, Spring Cloud, and Kubernetes.
The concept of design patterns is actually quite old; it was invented by Christopher Alexander back in 1977. In essence, a design pattern is about describing a reusable solution to a problem when given a specific context.
The design patterns we will cover are as follows:
- Service discovery
- Edge server
- Reactive microservices
- Central configuration
- Centralized log analysis
- Distributed tracing
- Circuit Breaker
- Control loop
- Centralized monitoring and alarms
We will use a lightweight approach to describing design patterns, and focus on the following:
- The problem
- A solution
- Requirements for the solution
Later in this book, we will delve more deeply into how to apply these design patterns. The context for these design patterns is a system landscape of cooperating microservices where the microservices communicate with each other using either synchronous requests (for example, using HTTP) or by sending asynchronous messages (for example, using a message broker).
Service discovery
The service discovery pattern has the following problem, solution, and solution requirements.
Problem
How can clients find microservices and their instances?
Microservices instances are typically assigned dynamically allocated IP addresses when they start up, for example, when running in containers. This makes it difficult for a client to make a request to a microservice that, for example, exposes a REST API over HTTP. Consider the following diagram:
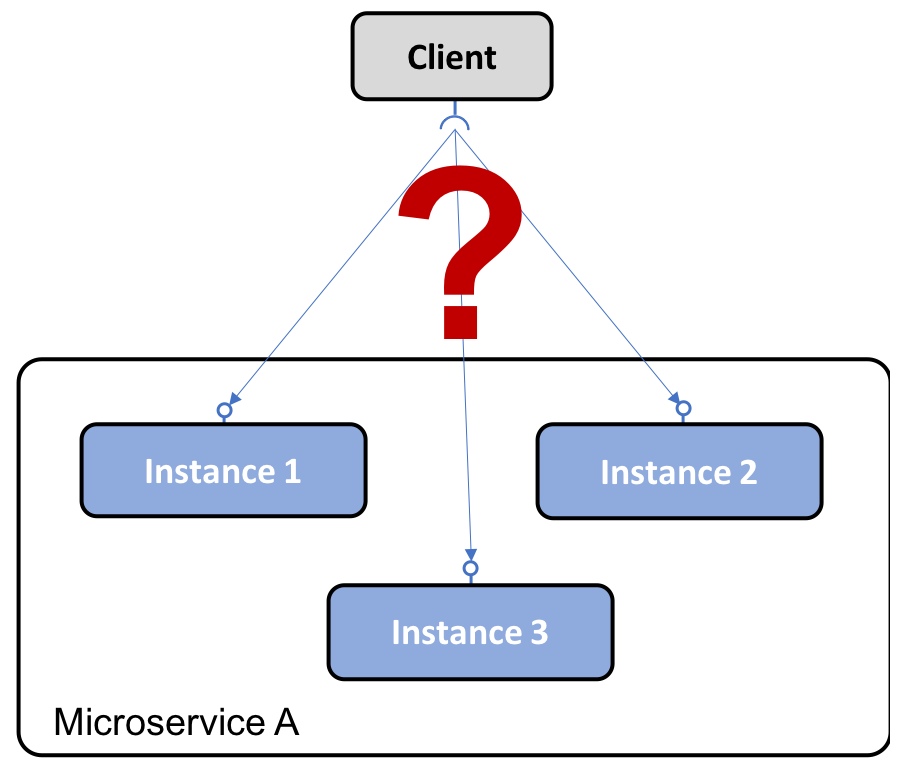
Solution
Add a new component – a service discovery service – to the system landscape, which keeps track of currently available microservices and the IP addresses of its instances.
Solution requirements
Some solution requirements are as follows:
- Automatically register/unregister microservices and their instances as they come and go.
- The client must be able to make a request to a logical endpoint for the microservice. The request will be routed to one of the microservices available instances.
- Requests to a microservice must be load-balanced over the available instances.
- We must be able to detect instances that are not currently healthy; that is, requests will not be routed to them.
Implementation notes: As we will see, this design pattern can be implemented using two different strategies:
- Client-side routing: The client uses a library that communicates with the service discovery service to find out the proper instances to send the requests to.
- Server-side routing: The infrastructure of the service discovery service also exposes a reverse proxy that all requests are sent to. The reverse proxy forwards the requests to a proper microservice instance on behalf of the client.
Edge server
The edge server pattern has the following problem, solution, and solution requirements.
Problem
In a system landscape of microservices, it is in many cases desirable to expose some of the microservices to the outside of the system landscape and hide the remaining microservices from external access. The exposed microservices must be protected against requests from malicious clients.
Solution
Add a new component, an Edge Server, to the system landscape that all incoming requests will go through:
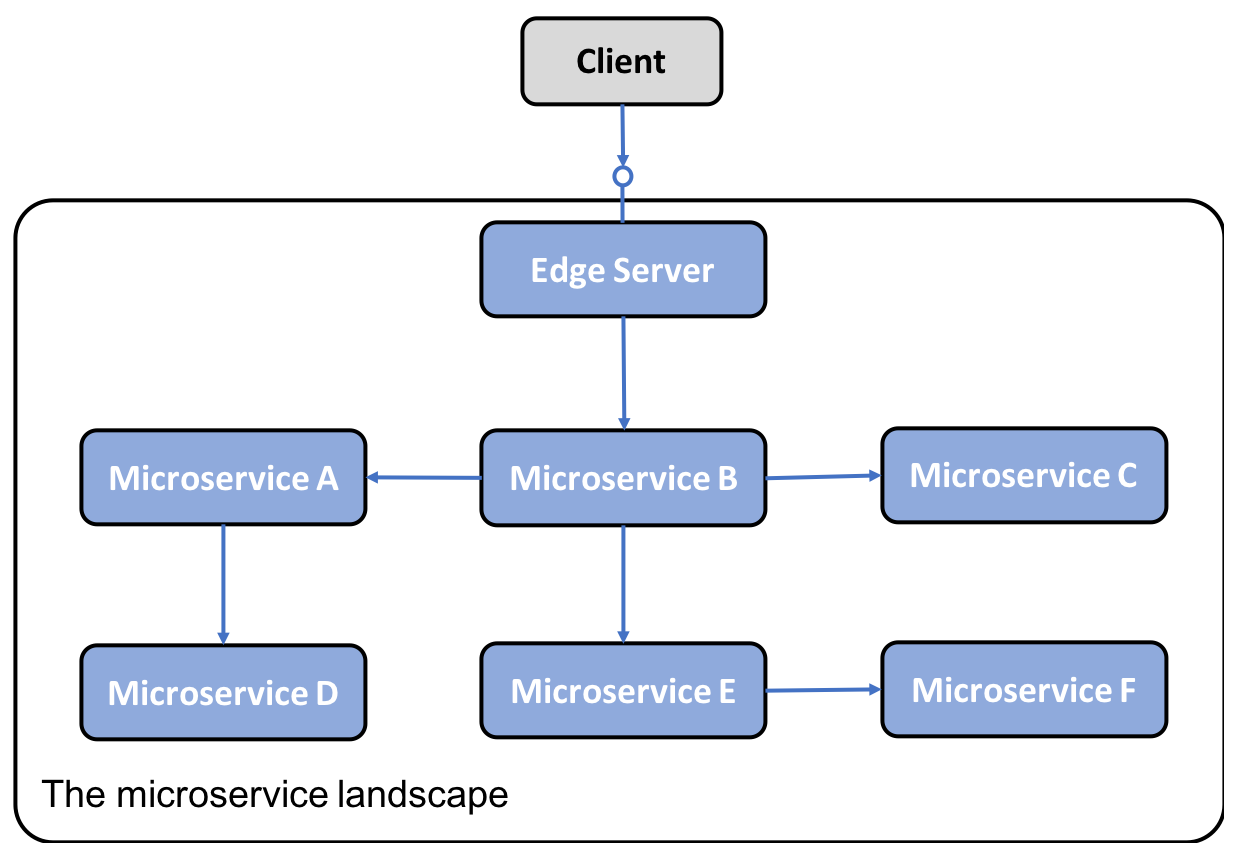
Implementation notes: An edge server typically behaves like a reverse proxy and can be integrated with a discovery service to provide dynamic load balancing capabilities.
Solution requirements
Some solution requirements are as follows:
- Hide internal services that should not be exposed outside their context; that is, only route requests to microservices that are configured to allow external requests.
- Expose external services and protect them from malicious requests; that is, use standard protocols and best practices such as OAuth, OIDC, JWT tokens, and API keys to ensure that the clients are trustworthy.
Reactive microservice
The reactive microservice pattern has the following problem, solution, and solution requirements.
Problem
Traditionally, as Java developers, we are used to implementing synchronous communication using blocking I/O, for example, a RESTful JSON API over HTTP. Using a blocking I/O means that a thread is allocated from the operating system for the length of the request. If the number of concurrent requests goes up (and/or the number of involved components in a request, for example, a chain of cooperating microservices, goes up), a server might run out of available threads in the operating system, causing problems ranging from longer response times to crashing servers.
Also, as we already mentioned in this chapter, overusing blocking I/O can make a system of microservices prone to errors. For example, an increased delay in one service can cause clients to run out of available threads, causing them to fail. This, in turn, can cause their clients to have the same types of problem, which is also known as a chain of failures. See the Circuit Breaker section for how to handle a chain-of-failure-related problem.
Solution
Use non-blocking I/O to ensure that no threads are allocated while waiting for processing to occur in another service, that is, a database or another microservice.
Solution requirements
Some solution requirements are as follows:
- Whenever feasible, use an asynchronous programming model; that is, send messages without waiting for the receiver to process them.
- If a synchronous programming model is preferred, ensure that reactive frameworks are used that can execute synchronous requests using non-blocking I/O, that is, without allocating a thread while waiting for a response. This will make the microservices easier to scale in order to handle an increased workload.
- Microservices must also be designed to be resilient, that is, capable of producing a response, even if a service that it depends on fails. Once the failing service is operational again, its clients must be able to resume using it, which is known as self-healing.
Central configuration
The central configuration pattern has the following problem, solution, and solution requirements.
Problem
An application is, traditionally, deployed together with its configuration, for example, a set of environment variables and/or files containing configuration information. Given a system landscape based on a microservice architecture, that is, with a large number of deployed microservice instances, some queries arise:
- How do I get a complete picture of the configuration that is in place for all the running microservice instances?
- How do I update the configuration and make sure that all the affected microservice instances are updated correctly?
Solution
Add a new component, a configuration server, to the system landscape to store the configuration of all the microservices.
Solution requirements
Make it possible to store configuration information for a group of microservices in one place, with different settings for different environments (for example, dev, test, qa, and prod).
Centralized log analysis
Centralized log analysis has the following problem, solution, and solution requirements.
Problem
Traditionally, an application writes log events to log files that are stored on the local machine that the application runs on. Given a system landscape based on a microservice architecture, that is, with a large number of deployed microservice instances on a large number of smaller servers, we can ask the following questions:
- How do I get an overview of what is going on in the system landscape when each microservice instance writes to its own local log file?
- How do I find out if any of the microservice instances get into trouble and start writing error messages to their log files?
- If end users start to report problems, how can I find related log messages; that is, how can I identify which microservice instance is the root cause of the problem? The following diagram illustrates the problem:
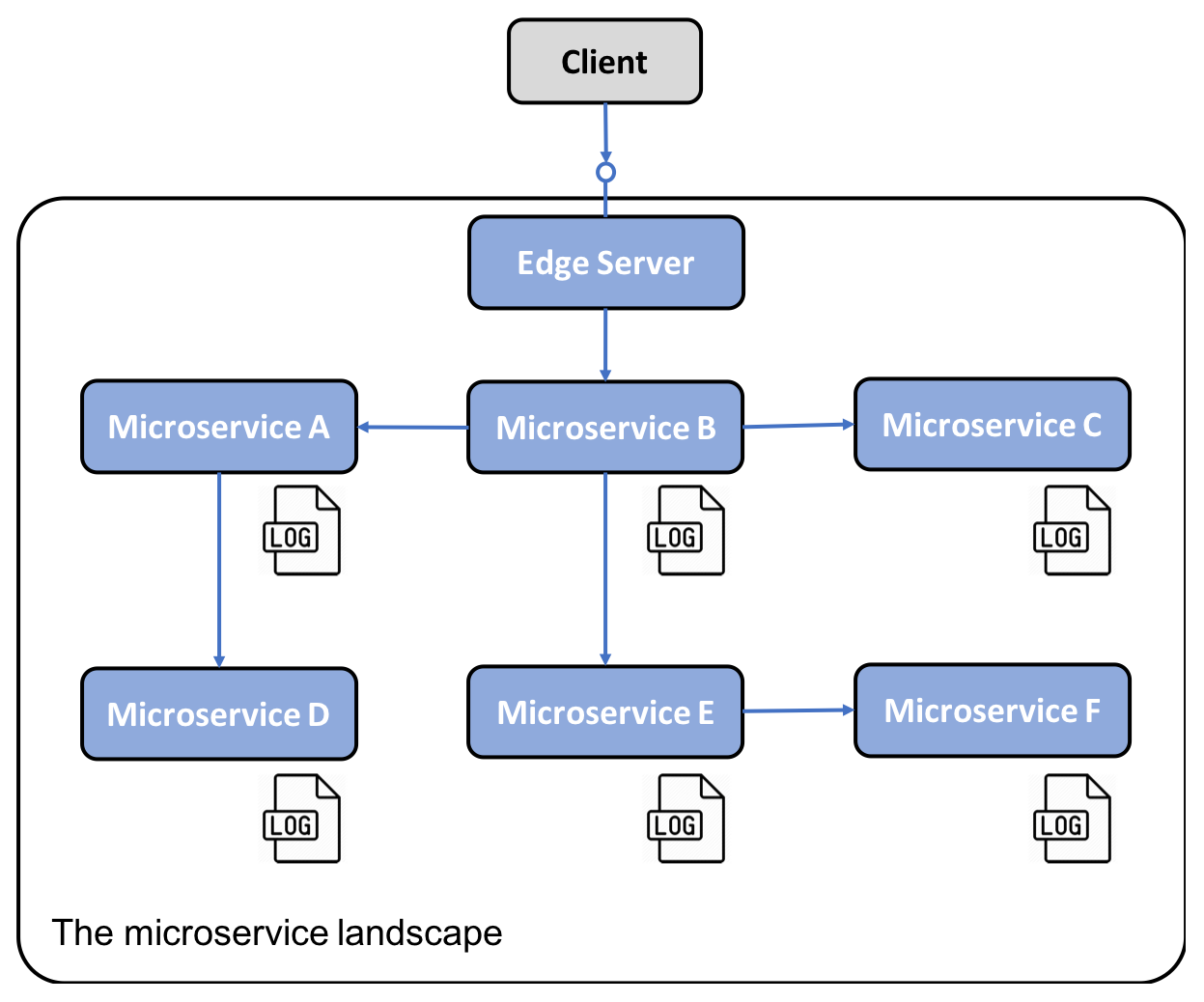
Solution
Add a new component that can manage centralized logging and is capable of the following:
- Detecting new microservice instances and collecting log events from them
- Interpreting and storing log events in a structured and searchable way in a central database
- Providing APIs and graphical tools for querying and analyzing log events
Distributed tracing
Distributed tracing has the following problem, solution, and solution requirements.
Problem
It must be possible to track requests and messages that flow between microservices while processing an external call to the system landscape.
Some examples of fault scenarios are as follows:
- If end users start to file support cases regarding a specific failure, how can we identify the microservice that caused the problem, that is, the root cause?
- If one support case mentions problems related to a specific entity, for example, a specific order number, how can we find log messages related to processing this specific order – for example, log messages from all microservices that were involved in processing this specific order?
The following diagram depicts this:
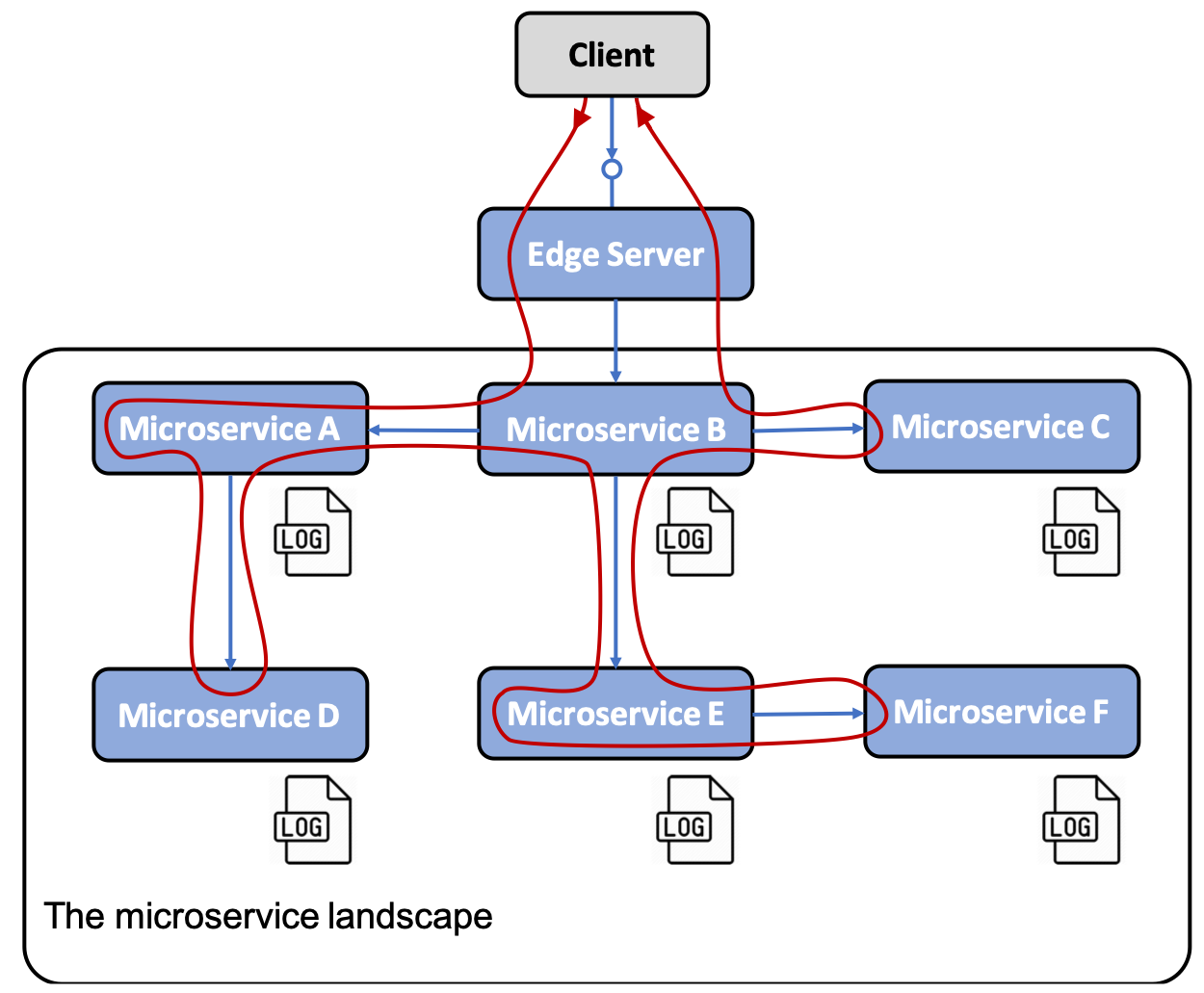
Solution
To track the processing between cooperating microservices, we need to ensure that all related requests and messages are marked with a common correlation ID and that the correlation ID is part of all log events. Based on a correlation ID, we can use the centralized logging service to find all related log events. If one of the log events also includes information about a business-related identifier, for example, the ID of a customer, product, order, and so on, we can find all related log events for that business identifier using the correlation ID.
Solution requirements
The solution requirements are as follows:
- Assign unique correlation IDs to all incoming or new requests and events in a well-known place, such as a header with a recognized name.
- When a microservice makes an outgoing request or sends a message, it must add the correlation ID to the request and message.
- All log events must include the correlation ID in a predefined format so that the centralized logging service can extract the correlation ID from the log event and make it searchable.
Circuit Breaker
The Circuit Breaker pattern will have the following problem, solution, and solution requirements.
Problem
A system landscape of microservices that uses synchronous intercommunication can be exposed to a chain of failure. If one microservice stops responding, its clients might get into problems as well and stop responding to requests from their clients. The problem can propagate recursively throughout a system landscape and take out major parts of it.
Solution
Add a Circuit Breaker that prevents new outgoing requests from a caller if it detects a problem with the service it calls.
Solution requirements
The solution requirements are as follows:
- Open the circuit and fail fast (without waiting for a timeout) if problems with the service are detected.
- Probe for failure correction (also known as a half-open circuit); that is, allow a single request to go through on a regular basis to see if the service operates normally again.
- Close the circuit if the probe detects that the service operates normally again. This capability is very important since it makes the system landscape resilient to these kinds of problems; that is, it self-heals.
The following diagram illustrates a scenario where all synchronous communication within the system landscape of microservices goes through Circuit Breakers. All the Circuit Breakers are closed; that is, they allow traffic, except for one Circuit Breaker detected problems in the service the requests go to. Therefore, this Circuit Breaker is open and utilizes fast-fail logic; that is, it does not call the failing service and waits for a timeout to occur. In the following, it immediately returns a response, optionally applying some fallback logic before responding:
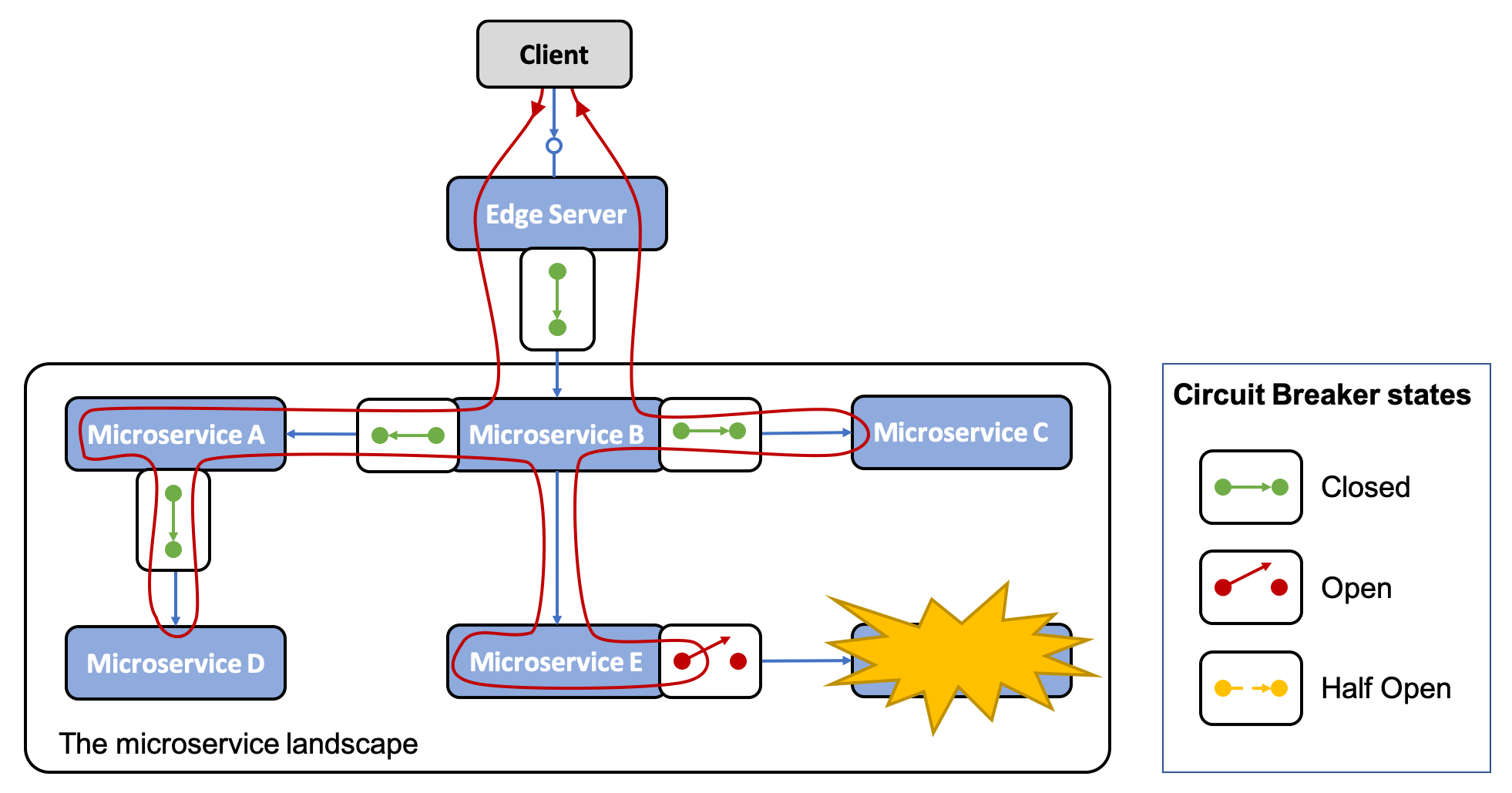
Control loop
The control loop pattern will have the following problem, solution, and solution requirements.
Problem
In a system landscape with a large number of microservice instances spread out over a number of servers, it is very difficult to manually detect and correct problems such as crashed or hung microservice instances.
Solution
Add a new component, a control loop, to the system landscape; this constantly observes the actual state of the system landscape; compares it with the desired state, as specified by the operators; and, if required, takes action. For example, if the two states differ, it needs to make the actual state equal to the desired state:
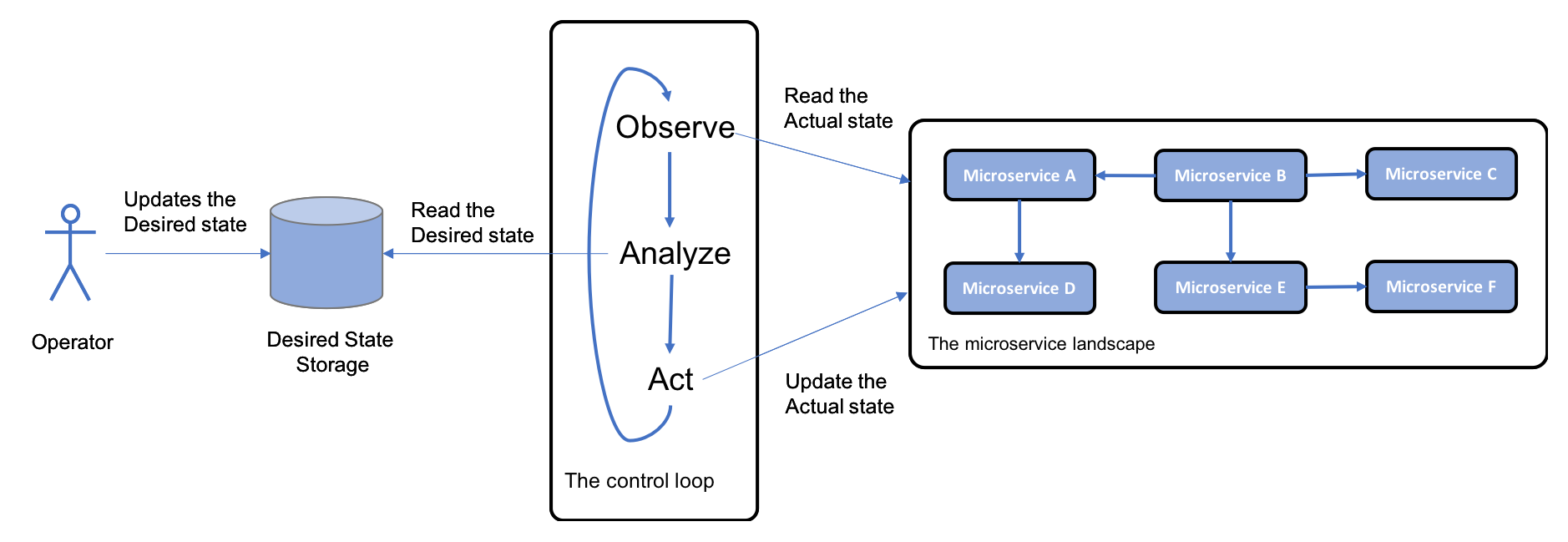
Solution requirements
Implementation notes: In the world of containers, a container orchestrator such as Kubernetes is typically used to implement this pattern. We will learn more about Kubernetes in Chapter 15, Introduction to Kubernetes.
Centralized monitoring and alarms
For this pattern, we will have the following problem, solution, and solution requirements.
Problem
If observed response times and/or the usage of hardware resources become unacceptably high, it can be very hard to discover the root cause of the problem. For example, we need to be able to analyze hardware resource consumption per microservice.
Solution
To curb this, we add a new component, a monitor service, to the system landscape, which is capable of collecting metrics about hardware resource usage for each microservice instance level.
Solution requirements
The solution requirements are as follows:
- It must be able to collect metrics from all the servers that are used by the system landscape, which includes auto-scaling servers.
- It must be able to detect new microservice instances as they are launched on the available servers and start to collect metrics from them.
- It must be able to provide APIs and graphical tools for querying and analyzing the collected metrics.
The following screenshot shows Grafana, which visualizes metrics from Prometheus, a monitoring tool that we will look at later in this book:
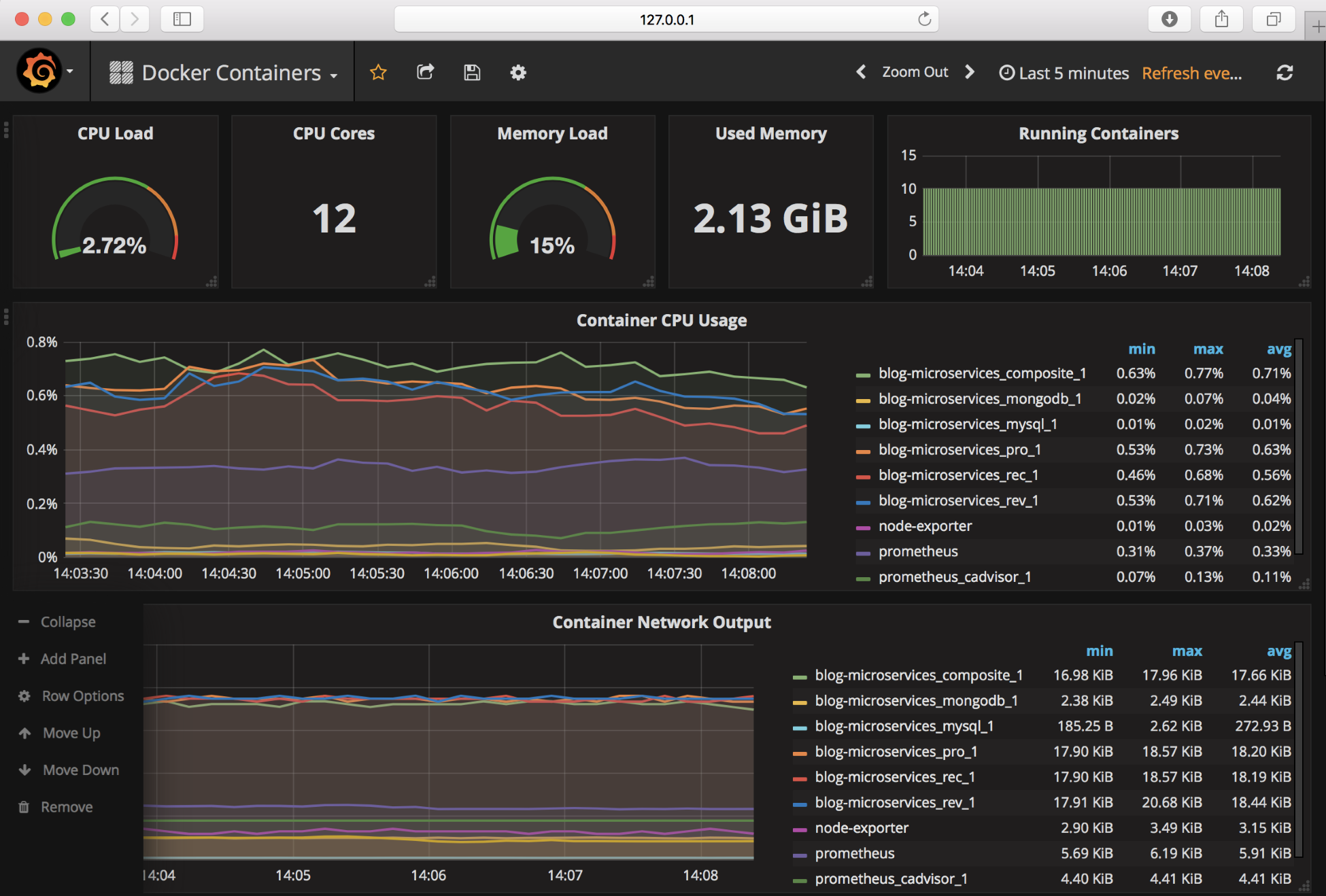
That was an extensive list! I am sure these design patterns helped you understand the challenges with microservices better. Next, we will move on to understand software enablers.




No comments:
Post a Comment