Automating infrastructure management helps to enhance control over a product’s environment, optimize resource use, and reduce spending on cloud infrastructure maintenance. With the right tool in place, you can describe infrastructure in code: create it once and simply copy it to new applications, making only a few changes.
In this article, we compare three tools that manage infrastructure as code: AWS Cloud Development Kit (CDK), AWS CloudFormation, and Terraform. We also show how to create and automate the management of cloud infrastructure in a way that we can later use on other projects.
This article will be useful for cloud infrastructure management and DevOps teams looking for a way to optimize their work as well as for those who want to learn how to use Terraform to automate infrastructure configuration.

Written by:
Vitalii L.,
DevOps Engineer,
System Programming Team

and
Sergei Zubkov,
QA Lead,
Software Testing Team
Contents:
Why manage infrastructure as code?
3 tools for managing AWS infrastructure as code
Configuring infrastructure for an AWS project with Terraform and Terragrunt
Conclusion
Why manage infrastructure as code?
IT infrastructure management oversees the performance of infrastructure elements needed for software to deliver business value. These elements include physical equipment like endpoints, servers, and data storage as well as virtual elements like network and app configurations, interfaces, and policies.
Usually, DevOps engineers are in charge of IT infrastructure. They need to keep it flexible, easily scalable, secure, and controllable. To achieve these goals, DevOps engineers containerize applications, deploying and managing them with tools like Docker.
Containerization allows for running an application in a manageable cluster without the need to manually configure the application and follow documentation step by step. Instead, engineers can use a Dockerfile to record changes and transfer code from one environment to another.
A containerized application can be deployed on a physical server, virtual machine, or cloud service. A cloud service is the most convenient option, since it comes with much more benefits than downsides:
Once an application is deployed in the cloud, DevOps engineers can start working on its infrastructure. Of course, they can do it manually, but that’s a bad development practice. Automating infrastructure management processes, on the other hand, helps you to experience the following benefits:
The infrastructure as code (IaC) approach allows DevOps engineers to simplify and automate the creation, management, and monitoring of software infrastructure. With IaC, DevOps engineers can describe infrastructure elements, required policies, and resources in machine-readable configuration files. These files allow engineers to streamline resource management, copy infrastructure from one project to another, and share project knowledge.
The key downside of using IaC is the risk of duplicating errors from the initial project infrastructure when reusing it. That’s why creating configuration files requires a great deal of planning and expertise working with IaC tools. And it all starts with choosing the right tool.
3 tools for managing AWS infrastructure as code
In this article, we’ll talk about managing AWS-based infrastructure and some of the tools you can use for this purpose. Particularly, we’ll go over:
AWS Cloud Development Kit, or CDK, is an open-source software development platform that allows you to specify resources for cloud applications. It ensures flexible management of containerized applications. It also allows DevOps engineers to write infrastructure code in JavaScript, TypeScript, Python, C#, Java, .NET, and Go.
On the downside, AWS CDK requires perfect knowledge of programming languages to be able to configure infrastructure properly. That creates an additional challenge for DevOps engineers, who usually don’t need a deep knowledge of programming languages.
AWS CloudFormation is an infrastructure as code solution that provides you with a simple way to model AWS and third-party resources, allocate infrastructure resources within minutes, and manage them during the whole lifecycle. The key benefit of AWS CloudFormation is its support of YAML configuration files. They help to easily organize infrastructure code.
The key downsides of AWS CloudFormation are that it only supports AWS cloud services and requires learning a specific syntax.
Terraform is an open-source tool that allows you to define and submit cloud infrastructure using the HashiCorp configuration language or JSON. Both have convenient and easy-to-understand syntax.
The key benefit of implementing cloud automation using Terraform is support for all major cloud computing services: AWS, Google Cloud Platform, Microsoft Azure, and DigitalOcean. Terraform also supports the Kubernetes API. Plus, it has detailed documentation and many ready-to-use modules.
For a better experience, use Terraform with Terragrunt — a wrapper that provides you with additional tools to store infrastructure configurations and allows you to use modules.
With these advantages, Terraform appears to be the most convenient choice to automate the management of cloud infrastructure. This tool is more versatile than AWS CDK or AWS CloudFormation, as it allows you to work with various cloud services and use ready-made modules. That’s why in our own cloud infrastructure management activities, we mostly rely on Terraform.
With that in mind, let’s see how to use Terraform to automate AWS cloud infrastructure configuration and management.
Configuring infrastructure for an AWS project with Terraform and Terragrunt
Configuring project infrastructure as code allows us to upload it to the repository that we’ll later use to deploy the application. Terragrunt stores temporary files and sensitive data in the cloud so we can access them from various machines and don’t have to upload them to Git.
Here’s how Terraform can automate AWS cloud infrastructure:
But first, we need to create the elements of our environment. To do it, let’s create the following files and folders at the root of our repository:
1. The terragrunt.hcl file contains most of the Terragrunt configuration information: the region, DynamoDB table for temporary variables, and bucket for status file storage.
Status files are Terraform’s artifacts that store data on created resources. At each launch, Terraform compares the current project infrastructure with the corresponding status file, applies changes, and edits this file.
2. The tfvars file is for creating basic variables applicable to all environments. For example, these can be SSH administrator keys.
3. The modules folder contains all the modules you use. With Terragrunt, you can use one module multiple times in different projects. You can also add third-party modules by adding a link to the corresponding repository or module branch.
4. The environments/qa folder contains HCL configurations for the QA environment. For example, with the following code, we can call the ACM module that creates project certificates:
5. The environments/qa/terraform.tfvars file is for all parameters that depend on the environment.
As soon as the infrastructure code is ready, we can apply it to any AWS account without the need for additional manual activities and get a consistent result:
After we get this result, we can start automating infrastructure deployments in the cloud no matter which cloud services our projects use.
Downsides of managing infrastructure with Terraform
Keep in mind that there are several limitations in managing cloud infrastructure using Terraform that we’ve discovered when using it in our projects:
- Complex configuration change management. When Terraform is actively used by several engineering teams, changing the project infrastructure with this tool may take more time than doing it manually. Any change in the configuration has to be committed to HCL files, tested, and implemented.
- Complex permission management. To be able to work with Terraform, DevOps engineers need an account with elevated access rights. It may be complicated to divide project infrastructure into several parts and configure access rights for DevOps engineers correctly and securely.
- Out-of-time deployment of product-specific features. Terraform developers often deliver features for AWS CloudFormation and other products later than you may expect.
Conclusion
Automating cloud infrastructure management can greatly reduce the amount of time and effort DevOps engineers put into configuring the infrastructure of cloud-based projects. With the right tools and approach, you can configure infrastructure once and then reuse it in other projects, making only the necessary changes.
In this article, we showed you how to automate infrastructure deployments in the cloud with Terraform. But the skills of our DevOps and cloud infrastructure management engineers go far beyond that. Feel free to reach out if you need to leverage our expertise in your project!It was originally published on https://www.apriorit.com/
It was originally published on https://www.apriorit.com/












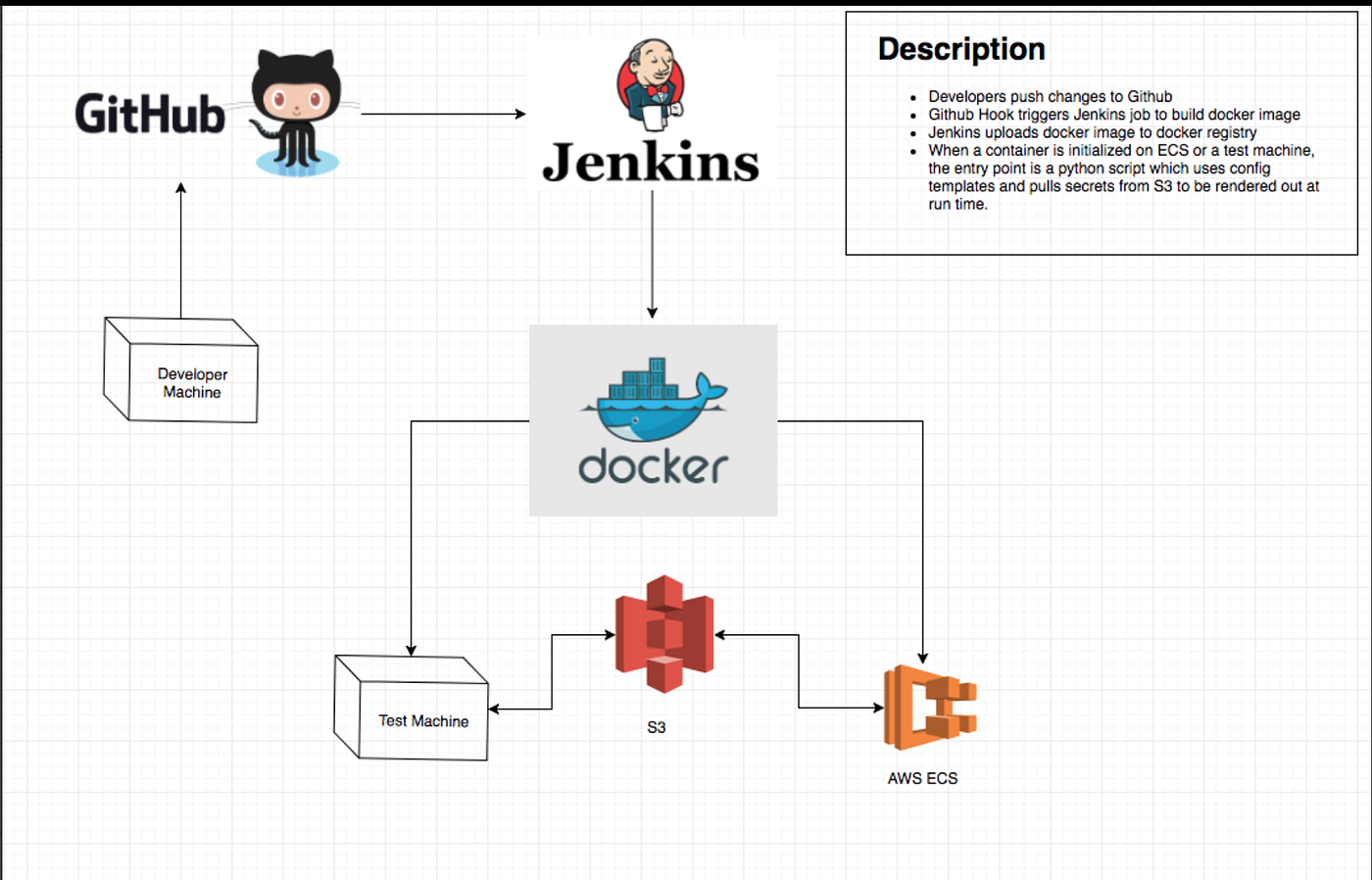 Sounds very appealing to have them manage one’s container applications with minimal effort. Since we had to migrate our services without a dedicated Ops resource we decided this service would be the best to host our services. Migration of the services to Amazon Elastic Container Service involved changing how we developed, built, and deployed services. All services that were stateful had to be refactored to be stateless to leverage autoscaling, where instances come and go. The migration process involved updating our tech stack to use the latest open source frameworks, deciding what AWS Services fit our use cases, development, coming up with a roll out strategy to prevent user disruptions, and cutting spend in the cloud. As part of the development, we migrated our services from using
Sounds very appealing to have them manage one’s container applications with minimal effort. Since we had to migrate our services without a dedicated Ops resource we decided this service would be the best to host our services. Migration of the services to Amazon Elastic Container Service involved changing how we developed, built, and deployed services. All services that were stateful had to be refactored to be stateless to leverage autoscaling, where instances come and go. The migration process involved updating our tech stack to use the latest open source frameworks, deciding what AWS Services fit our use cases, development, coming up with a roll out strategy to prevent user disruptions, and cutting spend in the cloud. As part of the development, we migrated our services from using 





