Treating your infrastructure as code is becoming more and more necessary these days. Writing these instructions becoming challenging too. In Azure we use ARM templates to define the resources and associate them with a deployment pipeline. But ARM templates are quite complicated and they are not everybody’s cup of tea.
Azure Bicep tries to resolve that and, after using it for a while I am so excited to do Bicep templates whenever I can. The dev experience using the bicep templates are highly satisfying.
What is Bicep?
Bicep is a domain specific language which declares your Azure resources to be deployed. It provides uncomplicated syntaxes and have been designed to reuse the code very easily through modules.
ARM templates Vs Bicep
We all have worked with ARM templates and one of its main “challenges” are depending on the resource you deploy you will need to know exactly what to configure and, this can be quite frustrating. With Bicep, the syntax is very concise. You just declare the resource and that’s that.
It’s kind of you going to a pizza shop and mentioning what’s the pizza you would like to have, the size of it, and the toppings. You don’t tell them how to make the pizza dough, or how to pick the jalapenos or which supermarket you want the meat from.
See the below Bicep template which will declare a consumption based app service.
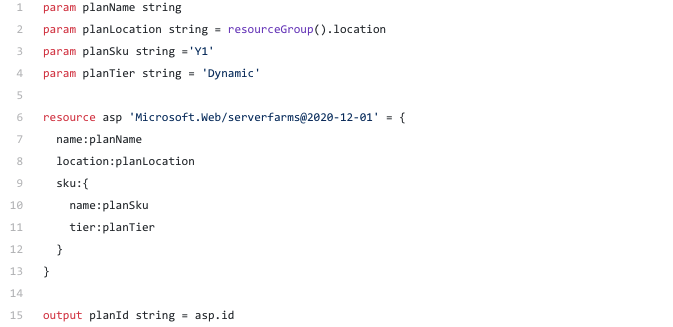
The same app service plan done using ARM template will look like below

The Bicep template is very straight forward, where as the ARM template syntax you need to be very explicit about what you require.
Bicep playground
A good starting point will be the Bicep playground. In there you can experiment with Bicep. The most important feature I like in there is that the ability to transform your existing ARM templates into Bicep . You can simply click the “Decompile” button and point to the ARM template. But be mindful that all your ARM templates might not be easily converted into Bicep templates. You just need to fix the errors which it will show you so generously.
Required tools
Absolutely love the Bicep extension! It has code snippets, syntax highlighting and, even intellisense!
You will find these features highly useful when building Bicep templates.
Resources required to deploy the function app
In here we are planning to deploy an Azure function app. First we’ll identify what are the resources required and create them using Bicep templates. Then like LEGO we’ll use these small building blocks to create the final template which we can use to deploy.
We will be using YAML based multi stage Azure DevOps pipeline to create the build and deployment pipeline.
To deploy an Azure function app you will need the below resources.
Storage account
Let’s start with the storage account.
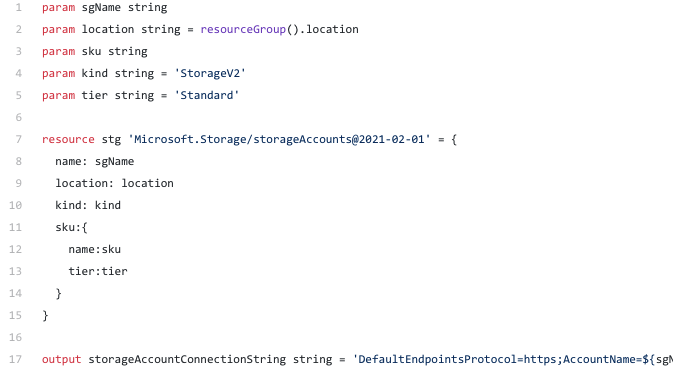
The storage account is so straight forward. You get the storage account kind and the storage account tier as parameters and use them to declare the storage account you require. Finally in the output section it outputs the connection string to the storage account.
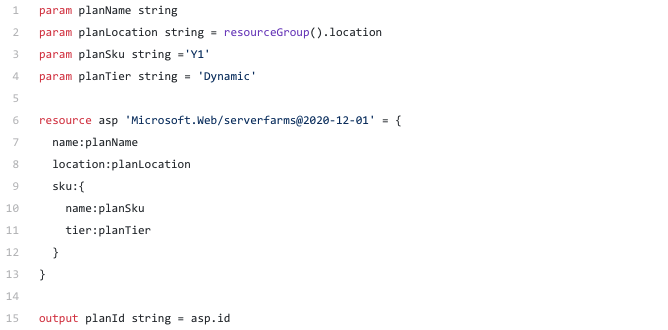
Application service plan
Every function app needs to be hosted. Most of the time this application service plan is already created and will be shared among other applications. But for this scenario I wanted to create a separate consumption based app service plan.
Application insights
Although this component is optional it’s highly recommended. The reason being you will be able to see your function app’s performance, failures in one central place.

Function app (without the settings)
First let’s create the skeleton function app without the settings. The key vault (next step) will need to know the function app’s principalid and the tenantid to provide access.
The function app which we’ll be creating will use deployment slots (azure function apps supports production and staging slots only).
So the below Bicep template creates function app with the two slots. Since the AKV will need the principalid and the tenantid the template will output them.

Key vault
Although a key vault can be optional, in reality when developing applications most of the time we’ll have some settings which we would like to make them securely accessible. You can use an Azure key vault to securely save and version your secrets. The below template is accepting the function app’s principalid and the tenantid to setup the access policies.

Finally it outputs the URI (the latest version) of the secret to be used.
Function app settings
Finally let’s set up the configurations required for the function app.

Using these building blocks together
Now we have all the building blocks to create the function app. Bicep has this cool feature where you can create modules. Now lets use Bicep modules to organize our resources to be deployed.


This is the storage account module
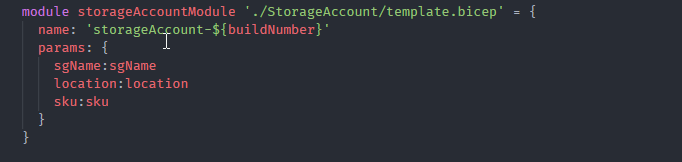
As you can see the syntax is very easy and straight forward. You define the module using the module keyword and the location for the Bicep template. Then you just simply pass the parameters required for the template. The Bicep extension of VSCode really helps you out here. As shown below the full intellisense is provided to you. It even give you a bunch of options including conditional access and my personal favourite required-properties .

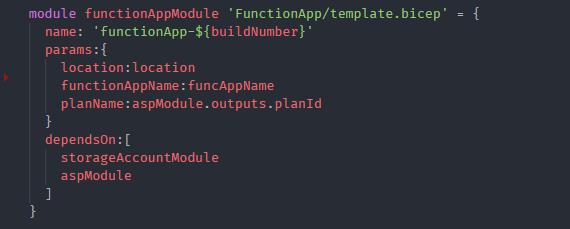
But when deploying the Azure resources you will need to know the dependencies between them when deploying. In our function app these are the dependencies when the Azure resources need to be deployed.
The dependencies among the Bicep modules are specified as DependsOn. The function app module dependencies can be defined as shown below.
Azure DevOps pipelines
Lets build a YAML based multi-stage pipeline to build and deploy our function app.
Build pipeline

The main purpose of a build pipeline is to check whether your code can be build successfully and to be able to create artifacts.
These are the steps associated with the build pipeline above,
Deployment pipeline
The steps involved in the deployment pipeline are as follows,
We’ll use AZURE CLI to create the resource group.
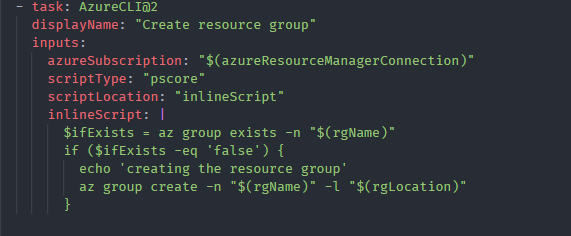
The resource group is created only if it doesn’t exist.
We have the main Bicep template which orchestrates all the required resources to deployed in Azure. You can use the same Azure CLI command to deploy resources, az deployment group create here.
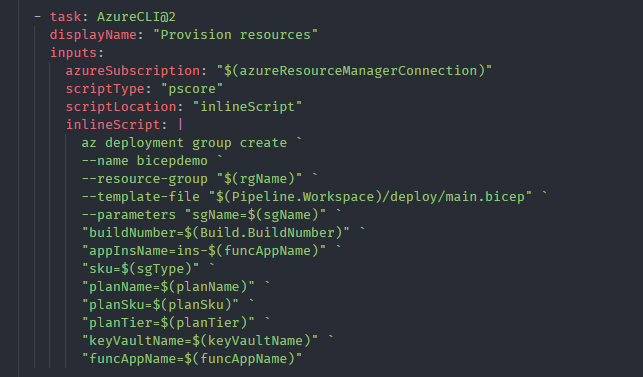
Notice the --template-file argument. Since we created all the Bicep templates as an artefact with the name deploy (see the build pipeline above) we can easily use it to locate the Bicep template. Then all the parameters which are required by the main.bicep template is passed.
Since we are deploying an HTTP triggered function app with slots, we need to deploy our code to the staging slot first. Let’s stop it first, secondly we’ll deploy the latest code there and then start the staging slot.
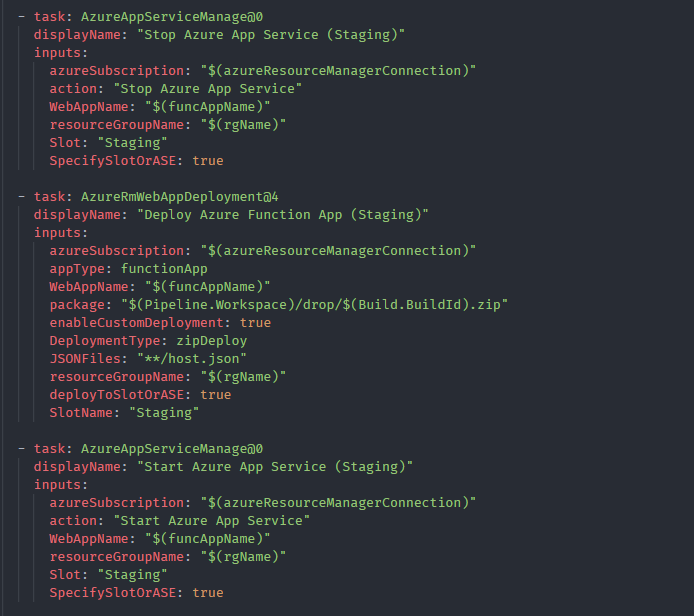
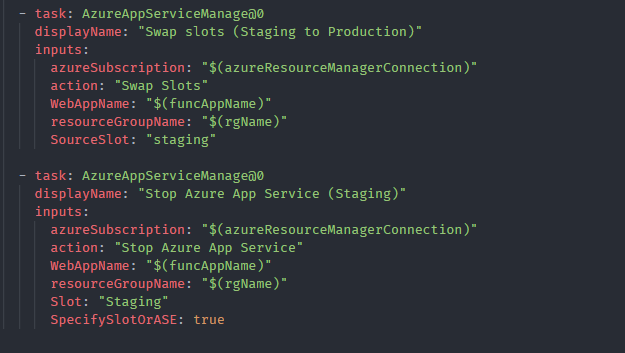
Since the staging slot is up and running, we can perform the swap operation with the production slot as specified above. Once it’s done no need to keep the staging slot alive. So as the final step we can stop the staging slot.
The build and deployment pipeline
Now we have a build pipeline and a deployment pipeline. In reality the applications we develop will be deployed in multiple environments. So let’s create the final piece where we can build and deploy the function app into multiple environments.
We’ll trigger the pipeline when the code is checked in to the master branch or to any branch under feature . Also for PR requests made comparing the code to the master branch (you can make these conditional for each environment as well).


As you can see above there are multiple stages in the pipeline,
BUILD -> DEV -> SITare the stages in this pipeline, but you can create other environments as stages in the pipeline as you wish. Notice how the variable files are placed. There’s one common.yaml file to store all the parameters and each [env].yaml file to override the parameter values which will be specific to the environment.
Setting up the pipeline in Azure DevOps
Create a new pipeline in Azure DevOps, but since you already have the files required please select the file which has instructions to build and deploy your solution before you finish creating the pipeline in Azure DevOps.
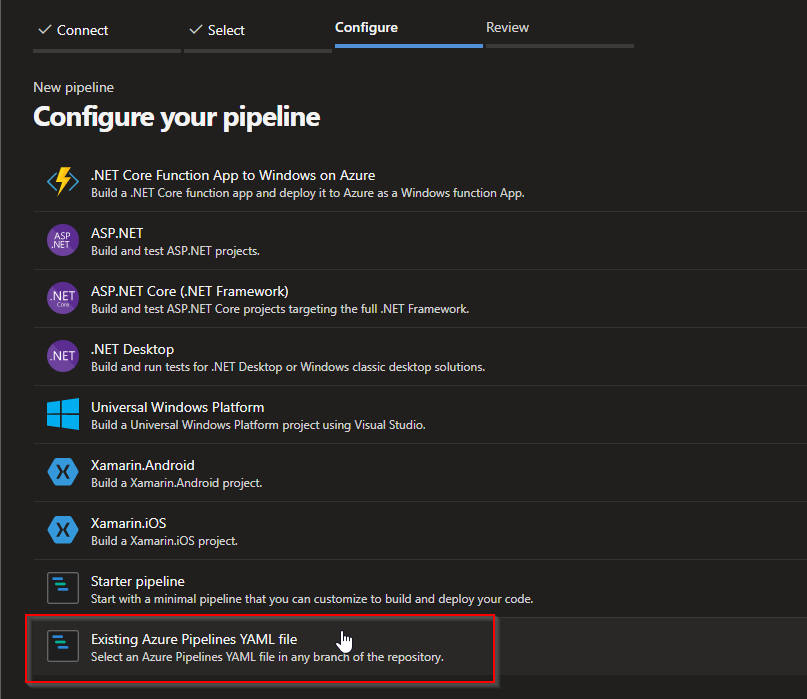
After running the pipeline, you will be able to see the resources successfully deployed in Azure.

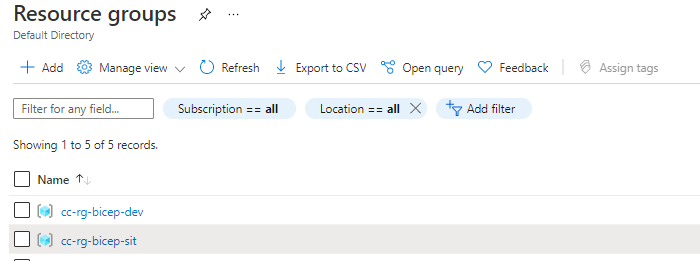
The created resource groups in Azure
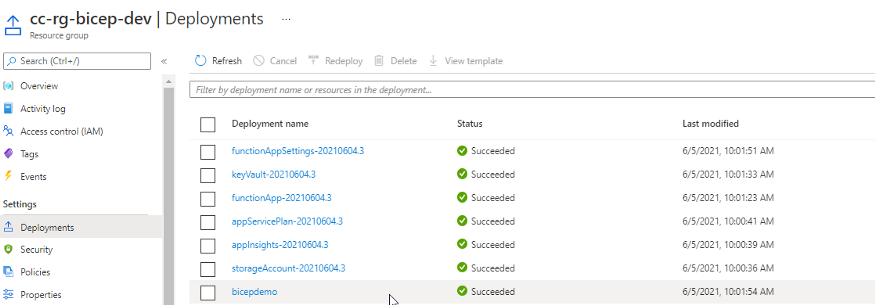
The deployment histories in resource groups.
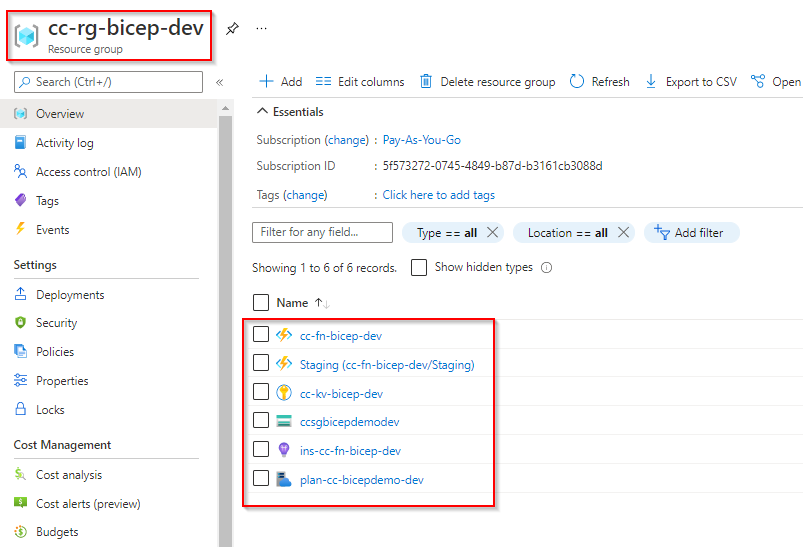
Finally, the resources deployed in the resource group.
Conclusion
Azure Bicep is awesome! The feature which I like most is the module support. VSCode and the Bicep extension is really helpful when you are building templates.
The code for this can be found in our GitHub
References
https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/overview