Using Docker commands in pipeline definition is nice, but has some drawbacks: First of all this approach suffers in speed of execution, because the container must start each time you run a build (and should be stopped at the end of the build). Is indeed true that if the docker image is already present in the agent machine startup time is not so high, but some images, like MsSql, are not immediately operative, so you need to wait for them to be ready for Every Build. The alternative is leave them running even if the build is finished, but this could lead to resource exaustion.
Another problem is dependency from Docker engine. If I include docker commands in build definition, I can build only on a machine that has Docker Installed. If most of my projects uses MongoDb, MsSql and Redis, I can simple install all three on my build machine maybe using a fast SSD as storage. In that scenario I’m expecting to use my physical instances, not waiting for docker to spin new container.
Including Docker Commands in pipeline definition is nice, but it tie the pipeline to Docker and can have a penalty in execution speed
What I’d like to do is leverage docker to spin out an agent and all needed dependencies once, then use that agent with a standard build that does not require docker. This gives me the flexibility of setting up a build machine with everything preinstalled, or to simply use Docker to spin out in seconds an agent that can build my code. Removing Docker dependency from my pipeline definition gave user the most flexibility.
For my first experiment I want also use Docker in Windows 2109 to leverage Windows Container.
First of all you can read the nice MSDN article about how to create a Windows Docker image that downloads, install and run an agent inside a Windows server machine with Docker for Windows. This allows you to spin out a new Docker Agent based on Windows image in minutes (just the time to download and configure the agent).
Thanks to Windows Containers, running an Azure DevOps agent based on Windows is a simple Docker Run command.
Now I need that agent to being able to use MongoDb and MsSql to run integration tests. Clearly I can install both db engine on my host machine and let docker agent to use them, but since I’ve already my agent in Docker I wish for dependencies to run also in Docker ; so… welcome Docker Compose.
Thanks to Docker Compose I can define a YAML file with a list of images that are part of a single sceanrio so I specified an Agent image followed by a Sql Server and a MongoDb images. The beauty of Docker-compose is the ability to refer to other container machines by name. Lets do an example: here is my complete docker compose YML file.
| |
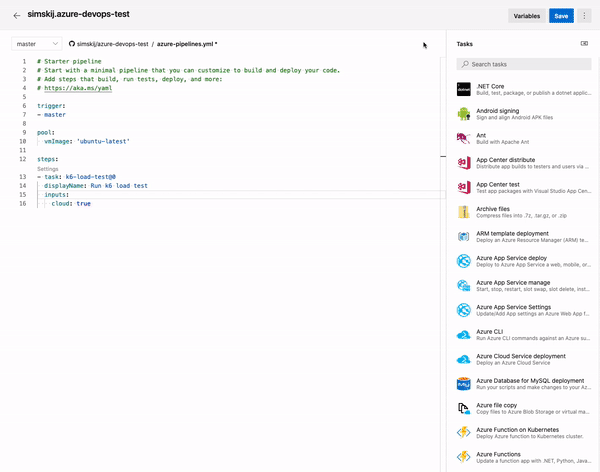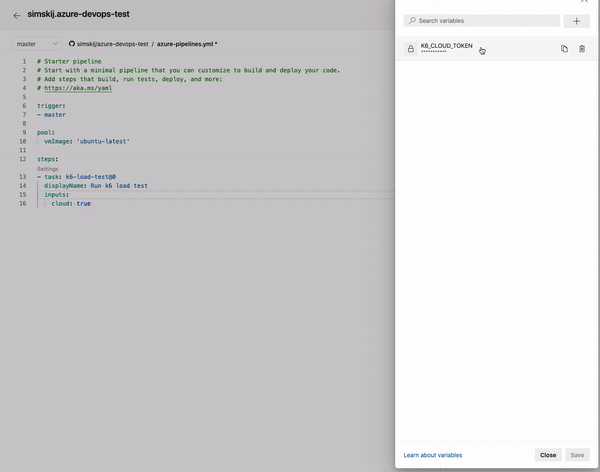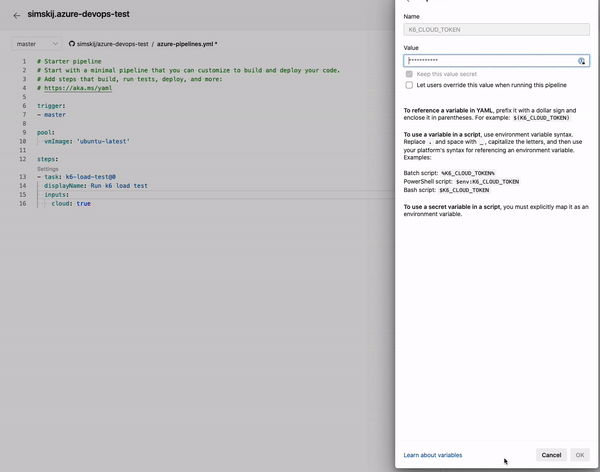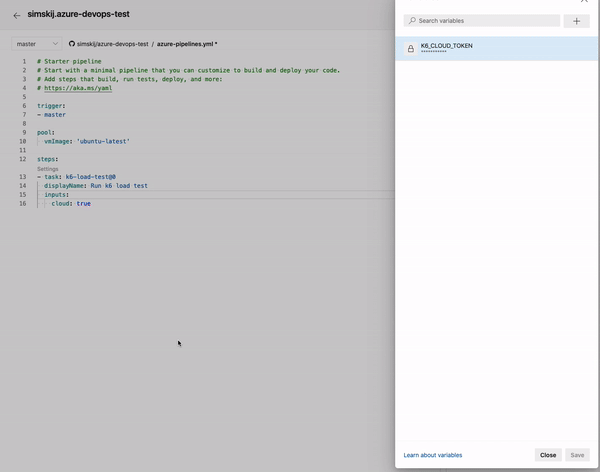
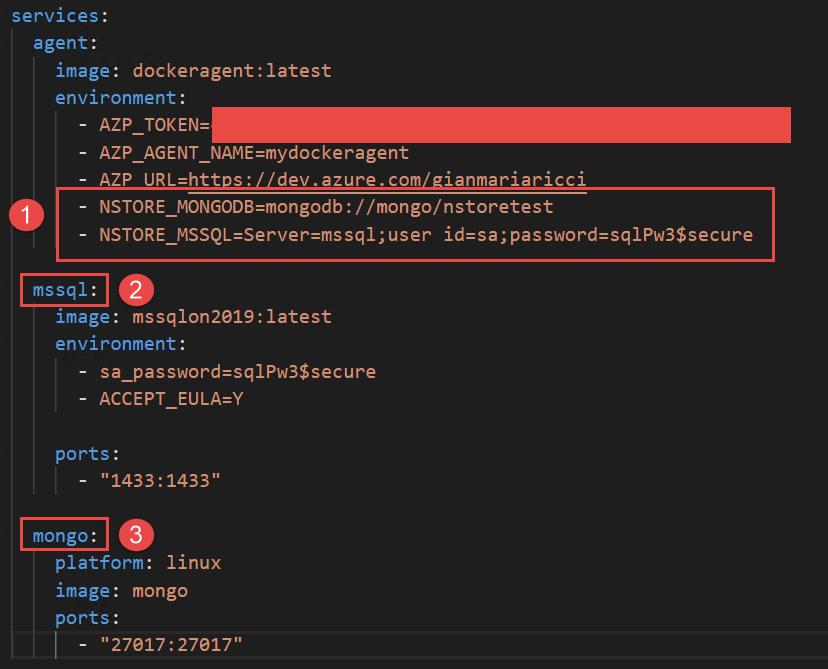
To simplify everything all of my integration tests that needs a connection string to MsSql or MongoDb grab the connection string by environment variable. This is convenient so each developer can use db instances of choice but also this technique makes super easy to configure a Docker agent specifying database connection strings as seen in Figure 1. I can specify in environment variables connection string to use for testing and I can simply use other docker service names directly in connection string.
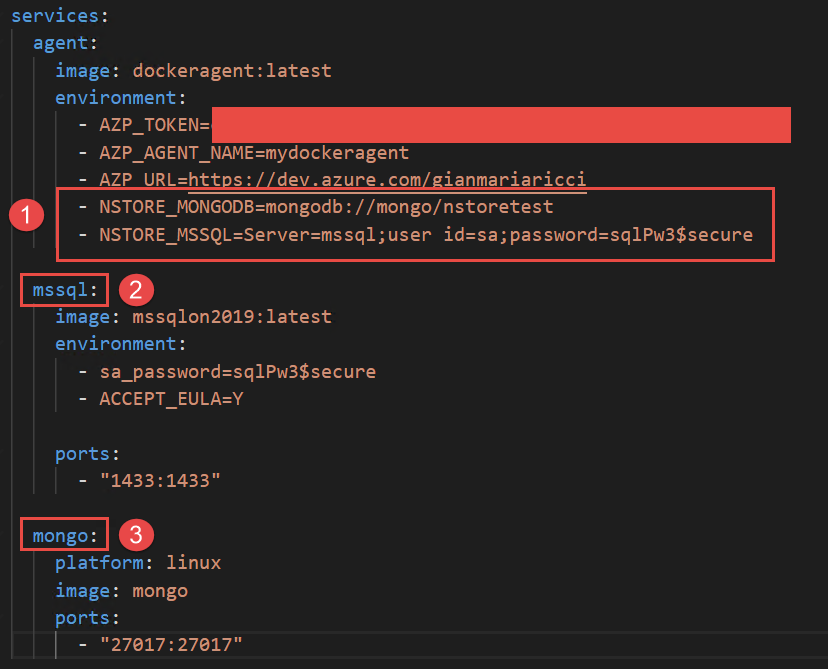
Figure 1: Environment variable to specify connection string.
As you can see (1) connection strings refers to other containers by name, nothing could be easier.
The real advantage of using Docker Compose is the ability to include Docker Compose file (as well as dockerfiles for all custom images that you could need) inside your source code. With this approach you can specify build pipelines leveraging YAML build of Azure DevOps and also the configuration of the agent with all dependencies. Since you can configure as many Agent you want for Azure DevOps (you actually pay for number of concurrent executing pipeline) thanks to Docker Compose you can setup an agent suitable for your project in less than one minutes. But this is optional, if you do not like to use Docker compose, you can simply setup an agent manually, just as you did before.
Including a docker compose file in your source code allows consumer of the code to start a compatible agent with a single command.
Thanks to docker compose, you pay the price of downloading pulling images once, also you are paying only once the time needed for any image to become operative (like MsSql or other databases that needs a little bit before being able to satisfy requests). After everything is up and running, your agent is operative and can immediately run your standard builds, no docker reference inside your YAML build file, no time wasted in waiting your images to become operational.
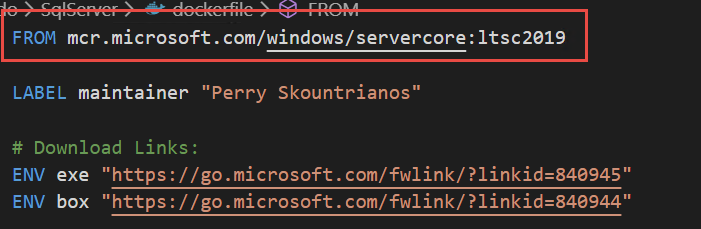
Thanks to experimental feature of Windows Server2019, I was able to specify a docker-compose file that contains not only windows images, but also Linux images. The only problem I had is that I did not find a Windows 2019 Image for Sql Server. I started getting error using standard MsSql images (build for windows 2016); So I decided to download official Docker file, change reference image and recreate the image and everything worked like a charm.
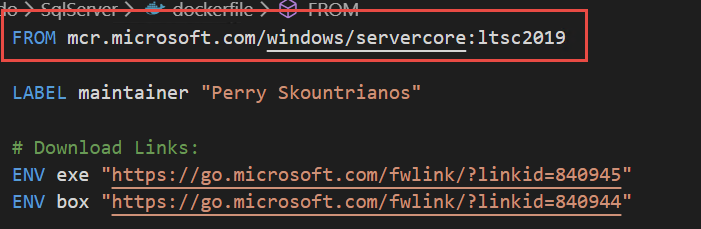
Figure 2: Small modification to Sql Server docker windows image file, targeting Windows Server 2019.
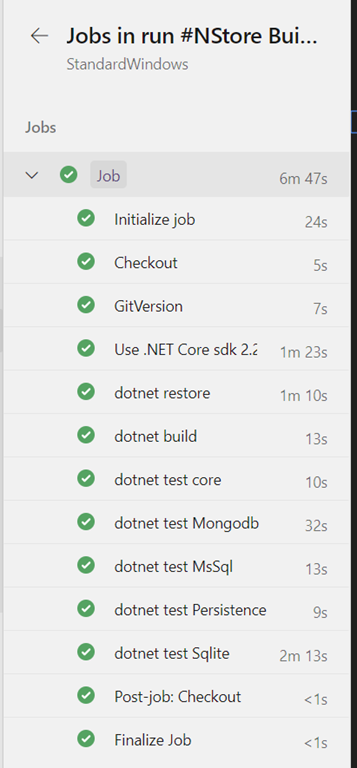
Since it is used only for test, I’m pretty confident that it should work and indeed my build runs just fine.
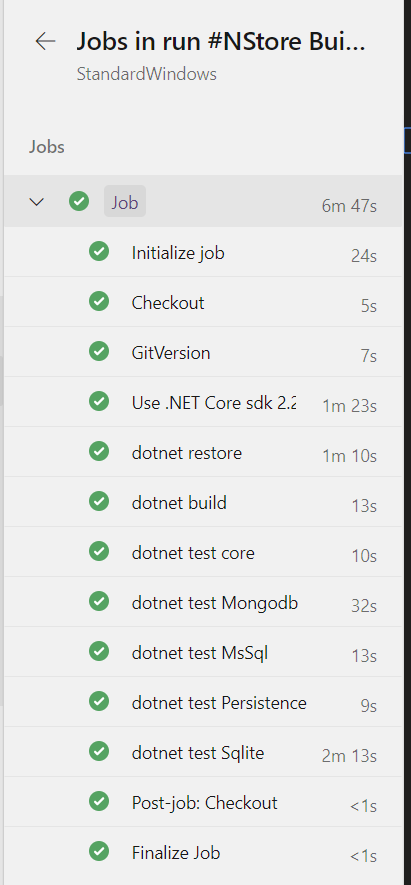
Figure 3: My build result, ran on docker agent.
Actually my agent created with Docker Compose is absolutely equal to all other agentw, from the point of view of Azure DevOps it has nothing different, but I’ve started it with a single line of Docker-Compose command
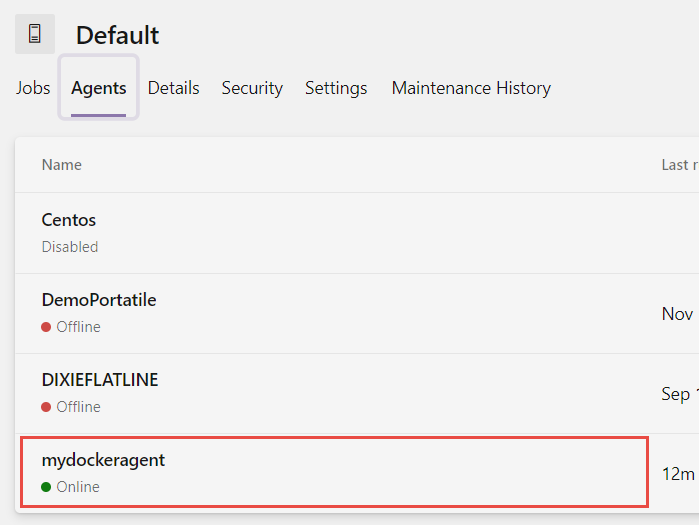
Figure 4: Agent running in docker it is treated as standard agents.
That’s all, with a little effort I’m able to include in my source code both YAML build definition as YAML Docker Compose file to specify the agent with all prerequisites to ran the build. This is especially useful for Open Source projects, where you want to fork a project then activate CI with no effort.











{kind=link}
{kind=link}
{kind=link}
{kind=link}